Att ha korrekta mått på inkomstfördelningen är en förutsättning för en konstruktiv diskussion om välfärdens utveckling, inte minst för att motverka de politiska krafter till höger och vänster som ofta avsiktligt misstolkar inkomstdata. Tyvärr syndar ibland även forskare, nu senast en amerikansk forskare vars nya inkomststatistikdatabas presenterats som bättre än föregångarna men vilket en närmare betraktelse inte ger stöd för.
Det var via Andreas Berghs hemsida som jag fick reda på den nya amerikanska databasen, med namnet “SWIID” (det är en förkortning för “standardiserad” WIID, där WIID i sin tur är en välkänd kollektion av allsköns oberoende inkomstfördelningsresultat från olika länder, några usla, andra bättre). Amerikanen hävdar att hans dataset “minimerar effekten av problematiska antaganden genom utgå från så mycket information som möjligt från näraliggande år från samma land” (min kursivering). Men en närmare titt på SWIID:s dokumentation visar att databasen inte innehåller nya, bättre data utan enbart ompaketerar gamla dataserier t ex genom att väga upp vissa observationer och skapa årsserier med hjälp av glidande medelvärden. Detta kan knappast vara att “minimera” de problem som de gamla serierna led av.
Hur levererar då den nya databasen SWIID i fallet Sverige? Ett test är att jämföra dess enda fördelningsmått, gini-koefficienten, med motsvarande mått från SCB:s inkomstfördelningsundersökning (data här). Serierna är inte helt jämförbara eftersom SCB studerar s k konsumtionsenheter (personer inom kosthushåll) med SWIID förmodligen bokföringshushåll. Och SCB:s disponibla inkomster innehåller realiserade kapitalvinster vilket SWIID förmodligen inte gör. Jag säger “förmodligen” eftersom SWIID:s dokumenation är urusel, vilket i sig är ett tecken på låg kvalitet.
Diagrammet nedan visar Sveriges gini 1991-2006 i SWIID och SCB . Varken trender eller nivåer stämmer överens. SWIID:s serie ligger inte bara betydligt lägre utan faller kraftigt 2001-06 medan den stiger i SCB:s serie. Än värre förefaller SWIID:s serie vara linjärt interpolerad mellan vissa år (se de spikraka strecken mellan 1993, 1996, 2000, 2004).
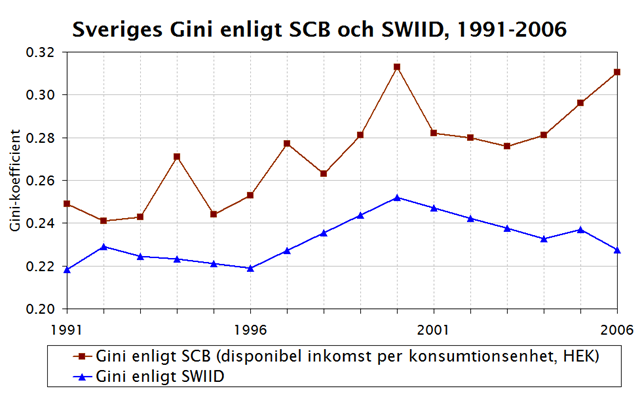
Slutsatsen är att SWIID-databasen inte håller vad dess upphovsman lovar. Tvärtom lider databasen av precis samma problem med “skit in, skit ut” som tidigare databaser (vilkas data SWIID också återanvänder). Den varning som inkomstfördelningsnestorn (och framtida nobelpristagaren?) Anthony Atkinson och Andrea Brandolini utfärdade för femton år sedan angående dessa internationella inkomstfördelningsdatabaser står sig med andra ord än idag:
We are not convinced that at present it is possible to use secondary datasets safely without some knoweldge of the underlying sources, and we caution strongly against mechanical use of such data-sets.

As the author of the dataset, I want to thank you, Daniel, for your post on the SWIID. Attention to the strengths and weaknesses of any data source can only be a good thing, and I have no illusions that the SWIID is perfect–nor are any data perfect for all purposes. As I write in my paper documenting the dataset, which perhaps you overlooked, the goal of the SWIID is to *maximize* comparability of inequality estimates across the *broadest possible* set of countries and years so as to provide *better* data than currently available for cross-national research.
Too often, current practice in cross-national research on inequality’s causes and consequences has been to uncritically use available data from the WIID (or worse, Deininger and Squire’s original compilation) while completely ignoring the basis–in net income, in consumption, by households, by individuals, and so on–by which the inequality statistics have been calculated. Because comparing household net income inequality in one country with individual consumption inequality in another can lead to very bad inferences, the SWIID uses a customized missing data imputation routine on the WIID to arrive at two series of estimates for household net income and household gross income inequality based on a common standard. The routine also provides series of standard errors for these estimates that researchers can incorporate into their analyses. By standardizing the data and including estimates of uncertainty, the SWIID is, I think, a big improvement on existing cross-national datasets, and its higher correlations with social indicators of inequality such as life expectancy and infant mortality rates supports this view.
Of course the data have weaknesses. Because the SWIID aims for the broadest possible coverage of countries and years, it relies on the previous data collection effort of the WIID rather than (as you correctly point out) collecting new, better data for the 153 countries over the five decades that are included in the dataset. That means that where data in the WIID is thin, such as for Sweden since 1994, the SWIID’s estimates will not be as good–reverting to something close to linear interpolation between available points–as where the WIID’s data is richer. In future versions of the SWIID, I hope to address this by supplementing the WIID data with other sources. But researchers interested in only a single country will always be able to find better sources than the SWIID. As I end my paper:
“I conclude by emphasizing that the SWIID represents a particular choice in the balance between comparability and coverage: it maximizes comparability for the broadest available set of country-year observations. This tradeoff will suit the needs of many scholars engaged in broadly cross-national research, but clearly it will not be the most appropriate option for all applications. Greater comparability can often be achieved when one’s scope of inquiry is narrower. The high quality, superior comparability, and great flexibility of the data available from the LIS will continue to make it the preferred source for many cross-national studies of inequality in the advanced countries. But even the LIS data are not perfectly comparable. Those investigating the development of income inequality over time within one or a few countries are therefore best advised to seek out the original sources cited in the WIID as well as other national sources and become familiar with the exact assumptions and definitions they employ (see Atkinson and Brandolini, 2001). Approaches using all of these data sources hold promise for improving our still-limited understanding of the causes and consequences of economic inequality.”
Best regards,
Fred
Dear Fred,
First, let me say that I think it’s really admirable–and pretty cool–that you contact on this matter. I mean, I wrote this blog post today–in Swedish!–with some critical remarks on your sizeable database and you immediately take the time to persuade me that things aren’t as bad as I might have insinuated. I think that’s a great scholarly attitude.
As for the data issues, I agree with you that there are indeed value added embedded in the SWIID data (as in the WIID), regarding the international income inequality estimates they provide. If we are willing to pay a price in terms of measurement-related uncertainty, one could even go as far as using (some of) these data for qualified analysis. I did read your paper (the one forthcoming in SSQ) and find your discussions about the database quite interesting and solid.
Still, what bothers me is when scholars, not yourself but possibly some of the users of your database, simply ignore the fact that many of the data points in the WIID data come from different sources and are based on different income concepts and income earning units. Those things matter a great deal for both the level and trends of income inequality, as you (but not necessarily all of the others) are well aware of.
Moreover, the construction of yearly estimates based on imputation and interpolation techniques strike me as brave, close to reckless. I have myself experimented with such exercises on the various top income databases that have appeared for some countries (I have written some papers using such data). In some cases, I think it is definately quite safe to construct an annual top 1% income share series using the annual variation of the top 0.1% income share and only a few single year estimates of the top 1% series. This would be motivated by the fact that the top 0.1% makes up about half of the top 1% and, more importantly, the sequences when we have both series they are correlated to >95%. However, I would be more hesitant to impute the top 0.1% series based on a top 5% series, since then the annual variation may differ quite a lot. Moreover, filling out the “global” holes with linear interpolations (straight lines) is even more problematic.
The imputation approach you use is not so common among economists, but I’ve seen variants of it elsewhere (e.g., in Ken Scheve’s and Dave Stasavage’s paper on long-run inequality and labor market institutions, forthcoming World Politics). Hence it’s partly a research cultural discrepancy and I leave it open as to which approach is the most appropriate one.
As I said, I have done some work on top income shares. While those observations are not as comprehensive in terms of inequality measurement as the Gini estimates in the SWIID are, they have some nice features. One advantage of the top income data is that they are based on roughly the same sources, income definitions and tax units over time and, at least ideally, between countries (the last one is not really true). Andrew Leigh at ANU has also an EJ paper showing that the annual variation of the top income shares quite closely matches WIID Gini series.
I think the SWIID data are better than the WIID data, and maybe you could show this by redoing Andrew’s analysis on your data and get an even closer match to the top income series?
Again, really nice to get this quick response from you. Good luck with promoting your database!
Ill just continue in english then 🙂
Daniel, your quote from the documentation is really unfair to Solt and his database. What he discusses here, is different methods to make different types of Gini coefficient comparable, and different methods to estimate missing data in series of Gini coefficients.
He is claiming that his estimation method, relying more on information close in time and in the same country is superior to other methods (such as assuming that Gini gross is always 3 point higher than Gini net, as actually suggested by Deininger & Squire. There is also a thing called SIID out there which also uses a less sophisticated method).
I agree with Solt here, and I would choose SWIID over both SIID and WIID.
Furthermore, due to the possibility of measurement errors in particular years, there is actually a possible upside to smoothing out the curve – if not perhaps in Sweden but in many countries whith less reliable statistics.
Andreas, as for the relative quality aspects of the SWIID database, I agree with you that the SWIID is most likely an improvement of the WIID data.
When it comes to absolute standards of SWIID’s inequality estimates, however, it is more difficult to assess quality. We all agree that the WIID data underlying the SWIID suffer from a number of problems, some smaller and some more serious. These are problems with both the level of inequality across countries and inequality trends within countries, largely due to different sources and methods used. And these problems do not go away just by avoiding to repeat some of the most awkward choices made by Deininger and Squire.
A better check of whether the SWIID is truly an improvement and not just some ambitious imputation exercise, is to make out of sample tests of its series.
And this is what I did for the Swedish net income Gini 1991-2006. The result was not that positive for the SWIID. (Another check, which I will write about shortly on this blog, would be to see if the full Swedish SWIID series from 1960 onwards works better). Of course, this is only one country observation and maybe the database works better for all other countries.
In the mean time, I strongly urge all users of SWIID to erase the Swedish net income Gini observations during 1991-2006 as they are clearly flawed.
I’ll second your comment, Daniel, about how cool it is that we can have this debate while separated by what? a quarter of the globe? and, to some degree, by language (thanks, Andreas, for continuing in English–Jag talar inte svenska–I’d otherwise have to rely on internet translation (which also provided the preceding declaration of ignorance)).
Despite all the help the internet provides, it seems to me that our different views on the SWIID are still a result of the different places we’re coming from. It is not at all surprising to me, Daniel, that you, as one who has written extensively about trends in inequality within Sweden, look at the Swedish series in the SWIID and see skit (that’s an easy word to pick up). As a country expert, of course you know of better series of data for Sweden.
But the goal of the SWIID is not to become a one-stop, be-all-end-all source for inequality data. It is to provide the best *cross-national* data–as I wrote above, quoting the paper, there are better sources to draw on if you just want to look at one country. Picking out the data on Sweden from the SWIID and comparing it to the data the SCB provides really risks missing the entire point. The SCB has *no* data on any country besides Sweden. It can provide *no* insight into the relative levels of inequality in Sweden compared to, say, Germany, Canada, and New Zealand, let alone Argentina, Tajikistan, and Thailand. *That* is the strength of the SWIID. From the perspective of one who wants to make that sort of comparison, to follow your “strongly urged” advice and delete the Swedish series from the SWIID because better data for Sweden exist elsewhere is simply to recommend against making any comparison of Sweden to other countries at all. And that sort of advice is rarely taken by comparativists like me: there are hundreds of articles–some *very* recent–that use the completely incomparable Deininger and Squire data! The SWIID, whatever its faults, is a better source for such work.
Now, your point about top income shares–which are available in Leigh’s dataset for 18 rich countries and, from other sources, perhaps a handful of others–is closer to the mark. I downloaded Leigh’s raw data, ran his do-files (which, not surprisingly, involve a good bit of interpolating and adjusting–it comes with the territory), then merged his data into the SWIID. Below, I present the pairwise correlations between Leigh’s data on income of the top 10% (share10) and top 1% (share1), plus ginis from Leigh’s filtered WIID v.2a data, Leigh’s sample of data from the Luxembourg Income Study (LIS), and the SWIID. The first table is all years; the second table is just the period covered by the SWIID, 1960 to the present (with apologies for the raw Stata output).
. pwcorr share10 share1 gini_wiid gini_lis gini_swiid, obs
| share10 share1 gini_wiid gini_lis gini_swiid
————-+———————————————
share10 | 1.0000
| 761
|
share1 | 0.8972 1.0000
| 761 937
|
gini_wiid | 0.4198 0.5008 1.0000
| 263 300 324
|
gini_lis | 0.7296 0.6248 0.6985 1.0000
| 63 63 66 68
|
gini_swiid | 0.6786 0.6209 0.7025 0.9922 1.0000
| 389 426 297 68 3351
|
. pwcorr share10 share1 gini_wiid gini_lis gini_swiid if year>=1960, obs
| share10 share1 gini_wiid gini_lis gini_swiid
————-+———————————————
share10 | 1.0000
| 460
|
share1 | 0.8210 1.0000
| 460 504
|
gini_wiid | 0.4357 0.4573 1.0000
| 248 277 300
|
gini_lis | 0.7296 0.6248 0.6985 1.0000
| 63 63 66 68
|
gini_swiid | 0.6786 0.6209 0.7025 0.9922 1.0000
| 389 426 297 68 3351
|
Leigh’s top-income shares do show a pretty high correlation with the LIS, which is justifiably considered the gold standard for cross-national inequality data. The relationship with the SWIID is nearly as high, and it is much higher than the WIID. Plus the SWIID offers many more observations in common with Leigh’s top income data than either the LIS or the WIID. And, even more importantly, the SWIID has observations for many, many countries for which top-income data is currently unavailable. Given that Leigh’s top-income data provide some insight into income distribution, it seems like a good source for studies of the rich countries. I’d probably want to see parallel analyses using gini data from the LIS or SWIID, though, if I were a reviewer. And if one wanted to expand one’s sample to include developing countries as well, there’s no contest: the SWIID is the dataset to use.
Anyway, dialog between country experts and those of us interested in cross-national comparisons is always helpful, I think. For one thing, as a result of this exchange, I’ll be sure to incorporate the SCB data for Sweden into the SWIID when I update it in a couple of months (believe me, I’m tempted to do it right now, but I think updating more than twice a year would only annoy users)–I had not realized how little data for Sweden was being incorporated into the SWIID. And I’ll see if I can figure out how to bring top-income shares into the imputation routine as well; I’d not seen Leigh’s dataset before. The SWIID will be an even better resource for cross-national research as a result.
In the meantime, I think the real question regarding inequality in Sweden is: Why does the SCB data show a sharp increase in inequality between 2004 and 2006, rising very nearly to 2000 levels (.310 to .313, 1% lower), that isn’t found in other sources? The EU Statistics on Income and Living Conditions show no change at all over this period (.23 in 2004, .23 in 2005, .23 in 2006), and the LIS shows a gini index 6% lower in 2005 than in 2000 (.237 to .252). An answer to that one would help both those interested primarily in Sweden *and* those interested in broad cross-national comparison.
All the best,
Fred
Dear Fred,
It’s great that you stand up for your database. It is also a nice signal that you are pragmatic regarding the series included in the SWIID. And it is very promising that you commit to continually update the database whenever new and (hopefully) better data series arise.
As for the general value added of the SWIID, your correlation analysis using Andrew’s top income shares indeed suggests that the SWIID is an improvement of the WIID. Although the top income share series are not unproblematic, they are particularly useful if one wishes to get a fairly plausible picture of the within country trends of income inequality. I mean, this was their original purpose.
FYI, there is still something fishy about the Swedish data. I have already shown that the net income Gini 1991-2006 is probably flawed. But also the SWIID’s gross income Gini for Sweden 1963-2000 seems clearly wrong. In this figure, I compare the SWIID series with another annual gross income Gini series, constructed by a Swedish researcher, Mats Johansson (see his paper in Swedish). Mats used tabulated distributions from the official statistics of Statistics Sweden (SCB). For comparability, I also added the Swedish top 1 percentile gross income share, based on my Journal of Public Economics-article with Jesper Roine using the same data.
The comparison shows that the SWIID Gini follows a completely different time series pattern than the other two, being much more jumpy. The correlation coefficients are also indicative, being 0.85 between Johansson’s Gini and Roine & Waldenström’s top 1% but -0.06 between Johansson’s and SWIID’s Gini series. (The underlying data for the comparison can be found here).
Finally, let me just say that I could consider using the SWIID data in my own research. The large number of countries offer a cross-country variation in inequality that no other database offers at the same level of quality. Still, I would first plot all the series to see if they make at all sense. Second, I would be careful with putting too much weight on the annual time series variation as it seems to be resting on a fair amount of imputation (although they may well be state of the art imputations!).
Dear Fred,
I know of a few others who’ve used the dataset, but you’re the first that I know of to use the dofile. I’m pleased you managed to figure it out.
Also, I think the interchange with Daniel is potentially quite complementary to your SSQ approach. Country experts not only know the best datasets, but have a sense of what changes in inequality over a given period are reasonable. For the next update, you might even think about soliciting a few more suggestions of this ilk (assuming you haven’t already).
Cheers,
Andrew.
Deleting Swedish data becuase the series do not fit the statistics Sweden data seems odd, as the same most likely holds for other countries.
In fact, because SWIID aims at international comparability, it must by definition differ from national series.
Another point:
The WIID is a collection of various inequality estimates, mostly Ginis, with info on from where they are taken, and to the extent possible, info on how they are computed (rural, nation wide, expenditure, income, consumption, gross, net et cetera).
It is not meant to be a database for international comparisons, unless you carefully select only comparable Ginis from it. And, as pointed out by Solt, several authors have ignored this, taking whatever they can find in WIID to maximize the number of observations.
Thus: The SWIID is not “most likely better” than the WIID, it is a completely different thing.
Andreas, I think your point that an internationally comparable series will be different from a national series that does not aspire to international comparability is a good one, but it really only applies to levels–trends over time should still be closely related. Daniel’s graph of gross inequality statistics suggests, at least to me, that the next version of the SWIID would really benefit from adding the Johansson data to the routine, and I’ll be sure to include them.
Which leads to Andrew’s point. (Again, this whole conversation demonstrates that the internet is *really* cool, doesn’t it? I had no problems at all with your code, Andrew, btw–thanks for posting it!) More data to input into my imputation routine is always better–it kicks out any uninformative series–and I’ve always favored adding more data as I came across them, particularly for countries that are relatively data-poor in the WIID (and, as I wrote above, I didn’t imagine that Sweden fell into that category! The problem, I’ve figured out since Daniel’s first post, is that whatever SCB data was included in the WIID was kicked out because it is listed as using a non-standard equivalence scale. I can deal with that easily enough in the future). I have to admit, though, that I’d hoped for a division of labor–that I would pretty much leave it to the UNU people to add more “raw” data to the WIID, and then I’d do my best to standardize it. I put together the SWIID because of my frustrations as a consumer of inequality data–and those I heard others express again and again–not because I really wanted to be a producer. Most of my work deals with how the context of inequality shapes people’s attitudes and behavior. That said, I completely agree that getting input from country experts like Daniel helps the SWIID. I’ll add a note to my webpage soliciting ideas for data sources not already included in the WIID. Do any of you have other ideas for getting more such suggestions?
Daniel, I’m very glad to read that you’re convinced that the SWIID would be potentially useful for your cross-national research! That’s all I aimed for. And I completely agree that one is always best advised to get familiar with one’s data before putting it to use.
This conversation has been very productive, I think, so I have a proposal. The WIID v.2c has some 2300 observations in 148 countries for income share of the top 10% (and 665 for the top 5%, though nothing on the top 1%, I’m afraid). Daniel and Andrew, would you be interested, as top-income scholars, in collaborating on a project to standardize these data? There will be imputation, Daniel, but I’ll handle that end. The resulting dataset (call it SWIID Top Incomes?) would provide cross-national researchers another indicator of inequality, and let top-incomes researchers expand to countries they otherwise are unlikely to get to for a while. What do you think–are you up for it? Let me know.
Best,
Fred