De senaste dagarna har ett rykte cirkulerat i forskarkretsar om att SCB tänker göra sig av med hela sin unika samling av svensk och internationell historisk statistik, inalles två hyllkilometer. Den internationella samlingen skulle troligtvis hamna utomlands, kanske i en depå i Nordnorge eller i Madrid, och därmed utom räckhåll för svenska bibliotekstjänster. Den svenska samlingen, som inte utgiven av SCB, skulle i värsta fall slängas. Biblioteket läggs troligtvis ned vilket påverkar både den interna och externa servicen. I ett mejlsvar från GD Stefan Lundgren har jag fått bekräftelse om att denna process är på gång, men även att SCB inte tänker göra någonting förhastat som exempelvis att splittra den internationella samlingen eller slänga svenskt material utan att först ha säkerställt att det finns bevarat i digital eller annan form. Men trots dessa besked återstår flera frågor. Att digitalisera allt svenskt material är ett stort projekt, och dessutom handlar det såväl om att skanna in som att överföra tryckta data till digitala databaser. Finns resurser avsatta för detta eller krävs extra anslag från staten? Och den övergripande frågan: Hur ser SCB på sin roll som myndighet med det yttersta ansvaret för både historisk och nutida statistik, en roll som man axlat ända sedan Tabellverkets dagar på 1700-talet? [Read more…]
Dags att SCB uppdaterar sitt historiska KPI
I början av 1930-talet publicerade Gunnar Myrdal ett index över svenska levnadskostnaders utveckling sedan 1830, vilket utgör grunden till SCB:s officiella historiska konsumentprisindex. Men nyare forskning har reviderat Myrdals siffror för tiden före 1914, och även lagt till nya konsumentpriser bakåt i tiden. Det är dags att SCB reviderar sin historiska KPI-serie.
För ett år sedan presenterade två ekonomhistoriker vid Stockholms universitet, Rodney Edvinsson och Johan Söderberg, en ny årlig KPI för Sverige mellan åren 1290 och 2010. Serien baseras på de allra senaste fynden inom historiska prisserier och drar även nytta av vad andra forskare kommit fram till under decennierna sedan Myrdal presenterade sin serie. Den nya serien och beskrivning av dess konstruktion finns fritt tillgänglig på Riksbankens hemsida här. Den har även genomgått akademisk kvalitetsgranskning och publicerats i en forskningsantologi på Riksbanken (som jag tidigare skrivit om här) och även som artikel i det senaste numret (2-2011) av Review of Income and Wealth.
För huvuddelen av perioden före 1800 baseras serien på varor som råg, havre, smör, järn, koppar, salt och öl. I figuren nedan visas den nya KPI-serien (blå linje) vid sidan av Myrdals original (röd) och en serie som lundahistorikern Lennart Jörberg konstruerade på 1970-talet (grön). Serierna är likartade, men notera att det skiljer sig inom delperioder och dessutom att Myrdals serie börjar först 1830.

Historiska konsumentpriser är betydelsefulla i dagens svenska ekonomi. De används för att kartlägga inflationens utveckling och därmed en rad viktiga makroekonomiska variablers reala utveckling. I takt med nya, bättre och längre tidsserier blir också den historiska dimensionen allt viktigare. Det är därför hög tid att SCB uppgraderar sin nuvarande historiska KPI-serie till den senaste och bästa som forskningen kan frambringa, nämligen den som Edvinsson-Söderberg presenterat.
Ökande bortfall hotar svensk välfärdsstatistik
Hur många är arbetslösa i Sverige? Hur ofta idrottar vi på fritiden? Hur många timmar per vecka ägnar vi åt obetalt hemarbete? För att kunna besvara frågor som dessa krävs att intervju- eller enkätundersökningar genomförs ute i befolkningen. Och för att statistiken ska bli meningsfull krävs att folk besvarar frågorna. Men så sker i allt mindre utsträckning.
På ett möte med SCB informerades jag nyligen om att bortfallet i SCBs olika undersökningar ökar, och det kraftigt. Lägst bortfall har flaggskeppet Arbetskraftsundersökningen (AKU) som bl a visar hur stor arbetslösheten är. Där struntar bara var åttonde svensk (ca 12%) att besvara frågor. Värre är det då för den viktiga Undersökningen om levnadsförhållandena (ULF) med ett bortfall som är nästan tre gånger större, 30-35 procent. Fast detta är ändå ingenting mot Tidsanvändningsundersökningen som i årets upplaga har ett bortfall på hela 60 procent!
Bortfallet är inte bara stort, det ökar. ULFs bortfall var ca 20 procent kring 1980. I SOFIs stora Levnadsnivåundersökning (LNU) var bortfallet ca fem procent 1968 medan det i år preliminärt ligger på ULFs nivå, ca 35%.
SCB står frågande inför denna oroande utveckling. Vad ligger bakom det ökande bortfallet? Här följer några tänkbara kandidater.
- Nummerpresentatörer, inte minst i mobiler, gör att man ser vem som ringer. Okända nummer – kanske särskilt från växlar – väljs bort. Eventuellt kan den ökande telefonförsäljningen bidragit till detta.
- Vissa grupper saknar fasta kontaktpunkter. Preliminära uppgifter från just LNU antyder att detta gäller särskilt gruppen nya i Sverige.
- Integritetsdebatter kan slå mot undersökningar av denna typ. Den s k Metropolitdebatten på 1980-talet var sannolikt orsaken till varför Folk- och Bostadsräkningarna skrotades. Kanske har FRA och IPRED gjort svenskarna ännu mindre svarsbenägna?
Problemet med bortfallet är allvarligt. Svensk ekonomisk politik bygger på statistiska uppgifter om medborgarnas välfärd, och om statistikens kvalitet brister kommer detta få allvarliga konsekvenser.
En utredning bör tillsättas – och det omgående. Även om flera myndigheter och departement har stort intresse i frågan känns det naturligast att det är SCB som tar ansvaret för att en sådan utredning. Bollen ligger hos Stefan Lundgren, SCBs generaldirektör.
Lurig inkomstfördelningsstatistik
Att ha korrekta mått på inkomstfördelningen är en förutsättning för en konstruktiv diskussion om välfärdens utveckling, inte minst för att motverka de politiska krafter till höger och vänster som ofta avsiktligt misstolkar inkomstdata. Tyvärr syndar ibland även forskare, nu senast en amerikansk forskare vars nya inkomststatistikdatabas presenterats som bättre än föregångarna men vilket en närmare betraktelse inte ger stöd för.
Det var via Andreas Berghs hemsida som jag fick reda på den nya amerikanska databasen, med namnet ”SWIID” (det är en förkortning för ”standardiserad” WIID, där WIID i sin tur är en välkänd kollektion av allsköns oberoende inkomstfördelningsresultat från olika länder, några usla, andra bättre). Amerikanen hävdar att hans dataset ”minimerar effekten av problematiska antaganden genom utgå från så mycket information som möjligt från näraliggande år från samma land” (min kursivering). Men en närmare titt på SWIID:s dokumentation visar att databasen inte innehåller nya, bättre data utan enbart ompaketerar gamla dataserier t ex genom att väga upp vissa observationer och skapa årsserier med hjälp av glidande medelvärden. Detta kan knappast vara att ”minimera” de problem som de gamla serierna led av.
Hur levererar då den nya databasen SWIID i fallet Sverige? Ett test är att jämföra dess enda fördelningsmått, gini-koefficienten, med motsvarande mått från SCB:s inkomstfördelningsundersökning (data här). Serierna är inte helt jämförbara eftersom SCB studerar s k konsumtionsenheter (personer inom kosthushåll) med SWIID förmodligen bokföringshushåll. Och SCB:s disponibla inkomster innehåller realiserade kapitalvinster vilket SWIID förmodligen inte gör. Jag säger ”förmodligen” eftersom SWIID:s dokumenation är urusel, vilket i sig är ett tecken på låg kvalitet.
Diagrammet nedan visar Sveriges gini 1991-2006 i SWIID och SCB . Varken trender eller nivåer stämmer överens. SWIID:s serie ligger inte bara betydligt lägre utan faller kraftigt 2001-06 medan den stiger i SCB:s serie. Än värre förefaller SWIID:s serie vara linjärt interpolerad mellan vissa år (se de spikraka strecken mellan 1993, 1996, 2000, 2004).
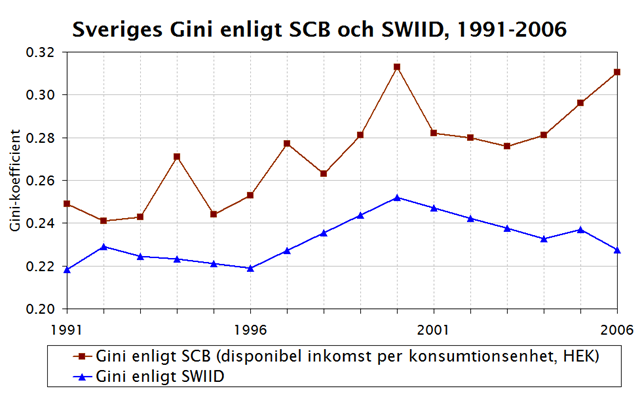
Slutsatsen är att SWIID-databasen inte håller vad dess upphovsman lovar. Tvärtom lider databasen av precis samma problem med ”skit in, skit ut” som tidigare databaser (vilkas data SWIID också återanvänder). Den varning som inkomstfördelningsnestorn (och framtida nobelpristagaren?) Anthony Atkinson och Andrea Brandolini utfärdade för femton år sedan angående dessa internationella inkomstfördelningsdatabaser står sig med andra ord än idag:
We are not convinced that at present it is possible to use secondary datasets safely without some knoweldge of the underlying sources, and we caution strongly against mechanical use of such data-sets.

Senaste kommentarer