Att ha korrekta mått på inkomstfördelningen är en förutsättning för en konstruktiv diskussion om välfärdens utveckling, inte minst för att motverka de politiska krafter till höger och vänster som ofta avsiktligt misstolkar inkomstdata. Tyvärr syndar ibland även forskare, nu senast en amerikansk forskare vars nya inkomststatistikdatabas presenterats som bättre än föregångarna men vilket en närmare betraktelse inte ger stöd för.
Det var via Andreas Berghs hemsida som jag fick reda på den nya amerikanska databasen, med namnet ”SWIID” (det är en förkortning för ”standardiserad” WIID, där WIID i sin tur är en välkänd kollektion av allsköns oberoende inkomstfördelningsresultat från olika länder, några usla, andra bättre). Amerikanen hävdar att hans dataset ”minimerar effekten av problematiska antaganden genom utgå från så mycket information som möjligt från näraliggande år från samma land” (min kursivering). Men en närmare titt på SWIID:s dokumentation visar att databasen inte innehåller nya, bättre data utan enbart ompaketerar gamla dataserier t ex genom att väga upp vissa observationer och skapa årsserier med hjälp av glidande medelvärden. Detta kan knappast vara att ”minimera” de problem som de gamla serierna led av.
Hur levererar då den nya databasen SWIID i fallet Sverige? Ett test är att jämföra dess enda fördelningsmått, gini-koefficienten, med motsvarande mått från SCB:s inkomstfördelningsundersökning (data här). Serierna är inte helt jämförbara eftersom SCB studerar s k konsumtionsenheter (personer inom kosthushåll) med SWIID förmodligen bokföringshushåll. Och SCB:s disponibla inkomster innehåller realiserade kapitalvinster vilket SWIID förmodligen inte gör. Jag säger ”förmodligen” eftersom SWIID:s dokumenation är urusel, vilket i sig är ett tecken på låg kvalitet.
Diagrammet nedan visar Sveriges gini 1991-2006 i SWIID och SCB . Varken trender eller nivåer stämmer överens. SWIID:s serie ligger inte bara betydligt lägre utan faller kraftigt 2001-06 medan den stiger i SCB:s serie. Än värre förefaller SWIID:s serie vara linjärt interpolerad mellan vissa år (se de spikraka strecken mellan 1993, 1996, 2000, 2004).
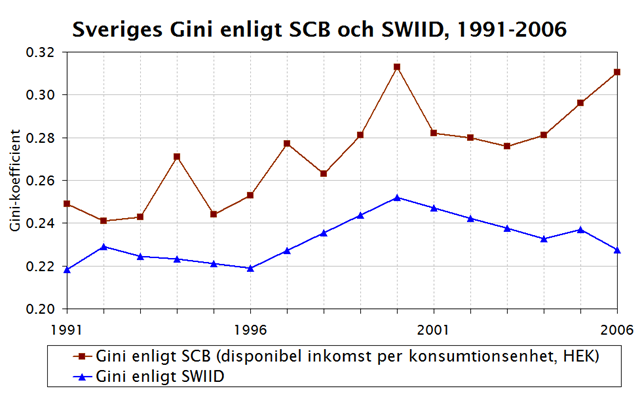
Slutsatsen är att SWIID-databasen inte håller vad dess upphovsman lovar. Tvärtom lider databasen av precis samma problem med ”skit in, skit ut” som tidigare databaser (vilkas data SWIID också återanvänder). Den varning som inkomstfördelningsnestorn (och framtida nobelpristagaren?) Anthony Atkinson och Andrea Brandolini utfärdade för femton år sedan angående dessa internationella inkomstfördelningsdatabaser står sig med andra ord än idag:
We are not convinced that at present it is possible to use secondary datasets safely without some knoweldge of the underlying sources, and we caution strongly against mechanical use of such data-sets.

Senaste kommentarer