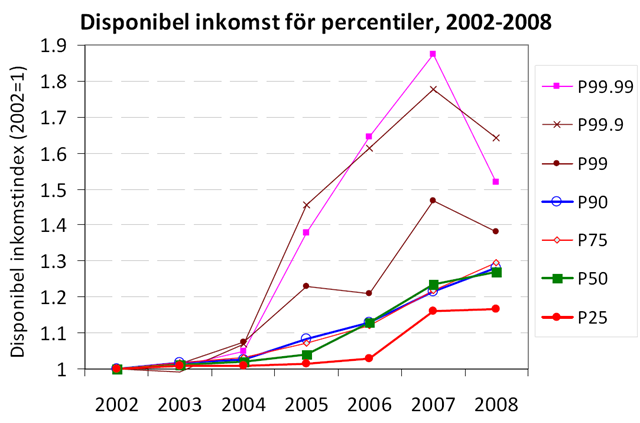
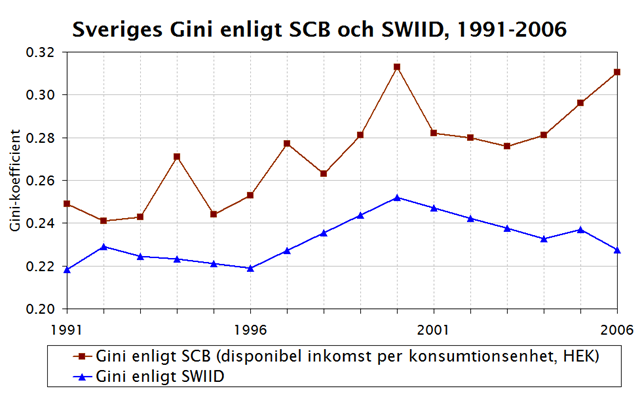
Vad får man om man om man korsar en svensk folkpartist med en finsk kommunist?* Svaret är en mycket läsvärd bok om inkomstfördelning. I 2011 års Välfärdsrapport redogör Anders Björklund och Markus Jäntti för inkomstfördelningen i Sverige både över tid och i jämförelse med andra länder. De visar bland att nedanstående graf över Gini-koefficienten för disponibel inkomst som visar att Sverige var som mest jämlikt 1980-1981:

De visar vidare att förklaringen till den ökade ojämlikheten därefter främst beror på ojämnt fördelade kapitalvinster.
I boken får man också veta hur bilden förändras om man istället analyserar inkomst över en längre tid, och hur stor betydelse familjebakgrunden har för framtida inkomster. Jag rekommenderar alla att läsa denna bok! (Läs också Ekonomistas Daniels ED-artikel tillsammans med Therese Nilsson om ojämlikhetens hälsoeffekter)
* Denna presentation av de bägge författarna har jag stulit från Markus Jäntti själv.


Senaste kommentarer