Tidskriften Basic and Applied Social Psychology beslutade nyligen att förbjuda p-värden i publicerade artiklar. Det finns mycket att säga om denna ganska drastiska åtgärd (se t ex Olle Häggströms blogginlägg), men det står helt klart att det finns problem med att fokusera alltför mycket på p-värden. Särskilt problematiska är p-värden när den statistiska styrkan (power) är låg i kombination med publiceringsbias, d.v.s. att framförallt statistiskt signifikanta resultat publiceras (se tidigare inlägg om publiceringsbias). Om den statistiska styrkan är låg, kan låga p-värden i vissa fall snarare vara en garant för missvisande resultat än ett tecken på tillförlitlighet.
Låt säga att vi vill studera effekten av att äta mycket spenat och fisk på framtida arbetsinkomster. Eftersom det är så oerhört många faktorer som påverkar arbetsinkomster är effekten av fisk och spenat förmodligen väldigt liten. Låt oss en smula optimistiskt anta att en extra portion spenat och fisk per vecka under barndomen leder till knappt 5 000 kronor i högre årlig inkomst som vuxen. Nedan illustreras en påhittad datamängd med 100 000 observationer där detta samband råder. Jag har antagit att spridningen i inkomst är stor (och följer en lognormal fördelning), medan variationen i hur mycket spenat och fisk folk äter är liten.
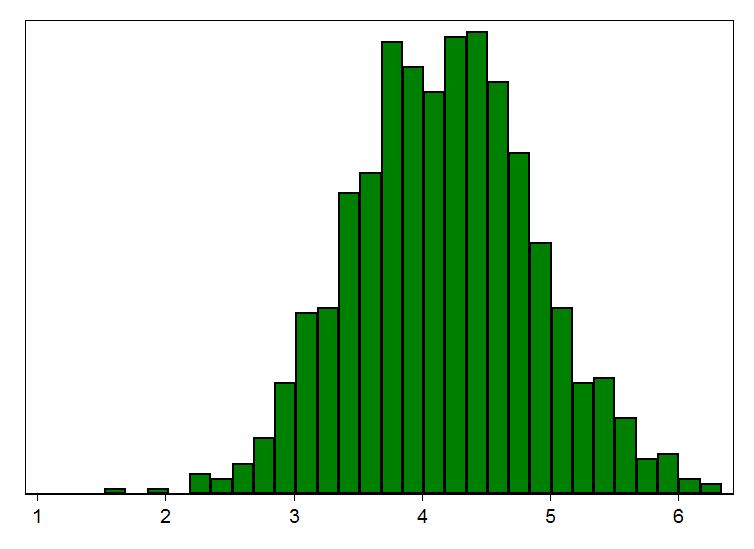
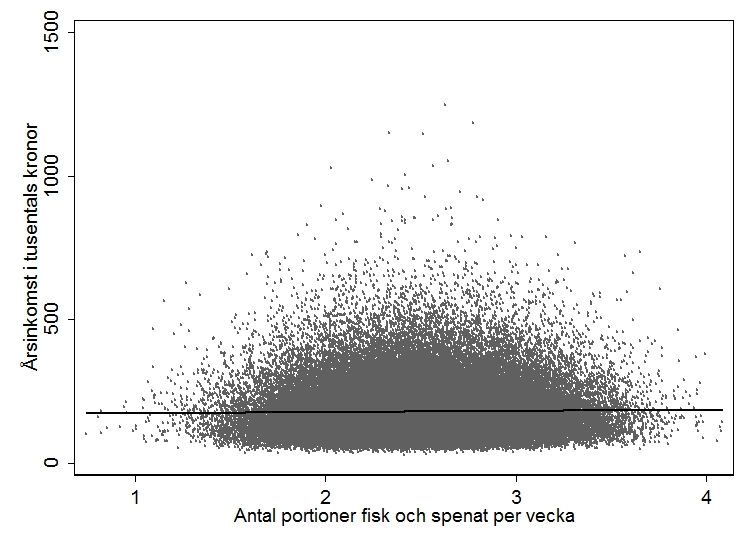 Låt oss bortse från andra problem som empiriker brottas med, t.ex. icke-slumpmässiga urval och svårigheten att skilja på korrelation och kausalitet, och låt oss anta att forskare gör studier på stora, slumpmässiga urval på 50 000 personer från denna population. Histogrammet nedan visar vad den skattade effekten skulle vara i 1 000 stycken sådana studier. I samtliga studier utom något enstaka fall skulle p-värdet vara under 5 procent och som synes av figuren skulle alla studierna rapportera effekter i närheten av den sanna effekten. Vissa studier skulle överskatta effekten, andra skulle underskatta den, men snittet av alla rapporterade resultat skulle ge en bra bild av den sanna effekten. I dessa studier är den statistiska styrkan nära 100 procent, d.v.s. studierna kommer alltid förkasta den falska nollhypotesen att det inte finns någon effekt.
Låt oss bortse från andra problem som empiriker brottas med, t.ex. icke-slumpmässiga urval och svårigheten att skilja på korrelation och kausalitet, och låt oss anta att forskare gör studier på stora, slumpmässiga urval på 50 000 personer från denna population. Histogrammet nedan visar vad den skattade effekten skulle vara i 1 000 stycken sådana studier. I samtliga studier utom något enstaka fall skulle p-värdet vara under 5 procent och som synes av figuren skulle alla studierna rapportera effekter i närheten av den sanna effekten. Vissa studier skulle överskatta effekten, andra skulle underskatta den, men snittet av alla rapporterade resultat skulle ge en bra bild av den sanna effekten. I dessa studier är den statistiska styrkan nära 100 procent, d.v.s. studierna kommer alltid förkasta den falska nollhypotesen att det inte finns någon effekt.
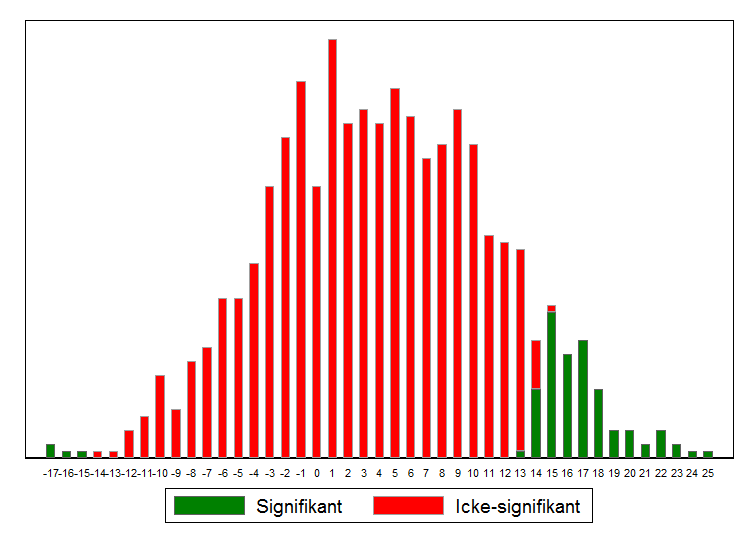
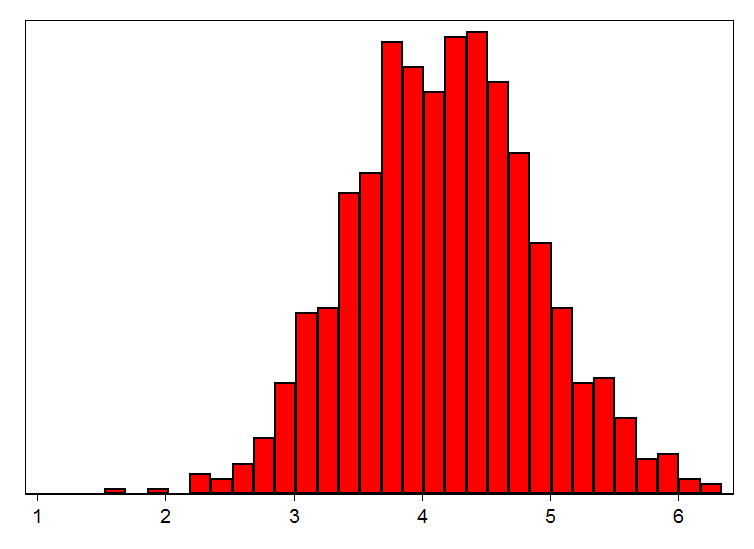
Låt oss nu i stället anta att forskare gör studier med ett betydligt mindre urval, kanske 1 000 stycken slumpmässigt utvalda personer, vilket inte är en ovanlig urvalsstorlek i till exempel enkätundersökningar. Om tusen sådana studier gjordes skulle den skattade effekten fördela sig enligt histogrammet nedan. De rödmarkerade staplarna visar skattningar där p-värdet är över fem procent och de gröna sådana där p-värdet understiger fem procent. Om bara studier med låga p-värden publiceras skulle alltså enbart skattningar där effekten kraftigt överdrivs eller har fel tecken publiceras. Statistiskt signifikanta effekter är antingen i storleksordningen 14 000-25 000 kronor per portion fisk och spenat eller så visar de att årsinkomsten minskar med ca 15 000 kronor per portion.
I en artikel i Psychological Science från förra året ges en rad handfasta råd samt en enkel programsnutt för att i efterhand räkna ut en studies statistiska styrka, men också en uppskattning av hur mycket effekten kan ha överskattats samt risken för att erhållit en skattning med fel tecken. I exemplet ovan är den statistiska styrkan 11 procent och villkorat på att en effekt är signifikant på femprocentsnivån kommer den ha fel tecken i 3.6% fallen och i snitt överskatta effekten med en faktor 3.5. Artikelförfattarna argumenterar för att empiriska studier genomgående bör redovisa denna typ av beräkningar.
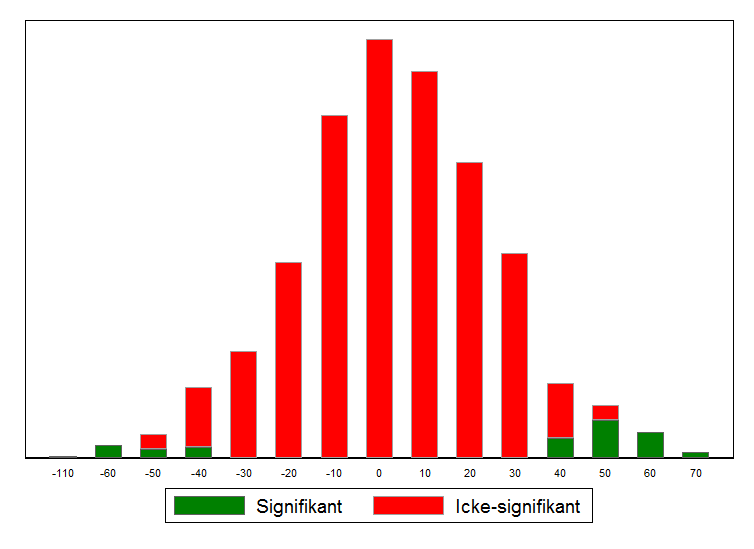
Problemet kan naturligtvis vara än värre. Kanske har en studie redan publicerats som redovisade en stor effekt av att äta fisk och spenat, och några forskare bestämmer sig därför att det är möjligt att studera effekten i ett experiment med ett hundratal deltagare. Om vi antar ett slumpmässigt urval på 100 personer skulle de redovisade effekterna vara rejält missvisande, vilket framgår av figuren nedan. I detta fall är den statistiska styrkan blott 6 procent, 26 procent av signifikanta skattningar kommer att ha fel tecken och storleken på effekten kommer att överdrivas med en faktor 10. Studier med signifikanta effekter skulle visa att effekten av en extra portion fisk av spenat antingen ökar eller minskar årsinkomsten med sisådär 50 000 kronor.
Mina resonemang ovan utgår från att jag vet vilken den sanna effekten är. I praktiken vet vi inte detta, vilket gör det svårt att bedöma vilken statistisk styrka en studie har. Likväl tror jag det vore klokt av både producenter och konsumenter av empirisk forskning att ägna lite mer kraft åt att beräkna studiers statistiska styrka och inte bara nöja sig med låga p-värden.
(STATA-kod för simuleringarna och figurerna ovan finns här.)

{kind=link}
Förmodar att du redan läst Häggströms sågning av tidskriftens BASPs beslut, men alla kanske inte gjort det: http://haggstrom.blogspot.se/2015/02/intellectual-suicide-by-journal-basic.html
Tack för tipset, jag hade inte läst det och lägger in en länk i ingressen i efterhand. Jag tycker också BASP:s beslut är konstigt eftersom man inte pekar på något alternativ. Jag håller också med Olle Häggström att det inte är något fel med p-värden/nollhypostestning i sig, utan att resultaten ibland tolkas felaktigt med tillägget att man ofta glömmer ta hänsyn till effekten av publiceringsbias.
Du missar en viktig sak och det är att testet bara är första steget. Nästa steg, om effekten är signifikant, är att uppskatta effekten samt hur bra vi har skattat den, tex via konfidensintervall. Så du har rätt i att punktskattningen blir orimlig men om du tittar på hela konfidensintervallet så blir den väldigt bred, från nära noll till enormt stor. Om effekten har ett konfidensintervall från 1000 till 99000 så skulle jag vara försiktig med att tro för mycket på punktskattningen 50000 även om den är signifikant.
Om du tittar på konfidensintervallet och därigenom gör en bedömning av skattningens precision är jag nöjd. Min erfarenhet är dock att det är ganska vanligt att fästa stor vikt vid punktskattningen och dra slutsatsen att ju lägre p-värdet är, desto mer tillförlitlig är punktskattningen. Min poäng är inte att säga att det är något ”fel” med p-värden, jag försöker bara illustrera en av de fallgropar om man obetänksamt stirrar sig blind på p-värdet.
Ett tillägg: Det är viktigt att konfidensintervallen tolkas på rätt sätt. I exemplet ovan kommer konfidensintervallen att inkludera den sanna effekten i 97% av fallen då skattningen inte är signifikant på femprocentsnivån, medan den sanna effekten bara kommer att ilgga inom konfidensintervallet i 79% av fallen då effekten är signifikant. Bland alla skattningar så ligger den sanna effekten förstås inom konfidensintervallet i 95% av fallen, men detta gäller inte längre när man villkorar på ett visst p-värde. Detta är självklarheter, men jag tror det lätt glömms bort i praktiken.
Bra och viktigt inlägg!
Att sluta använda stjärnor i regressionstabeller och att inte tolka resultat i termer av signifikans tycker jag personligen är något som alla som sysslar med tillämpad forskning bör göra. I mina ögon är två saker relevant; vad den bästa skattningen av effekten är (koefficienten) och hur precis den är (standard felet). P-värden säger oss inget om detta, enbart vad sannolikheten är att något är skilt från noll. Detta är oftast irrelevant inom nationalekonomi (och säkert många andra forskningsfält också).
I övrigt har Häggström en poäng från ett strikt statistiskt och matematiskt perspektiv. Men baserat på hur forskningsverkligheten fungerar, med publiceringsbias och få replikationsstudier, samt det faktum att våra hjärnor verkar ha svårt att hantera sannolikhet och slumpmässiga samband (detta baserar jag på de sammanfattningar av modern psykologisk forskning jag läst, såsom Kahnemans ”Thinking Fast and Slow”) så verkar det som att något måste göras. Det som föreslås i det här blogginlägget tycker jag helt klart vore ett steg i rätt riktning.
Diskussionen ovan känns ganska förvirrad. Givet att man antar en normalfördelning så är p-värden, standardfel och konfidensintervall bara olika sätt att mäta samma sak. Antingen får man förkasta samtliga mått eller inga av dem. Många samhällsvetare har ganska liten förståelse för detta dock.
Se till exempel http://www.bmj.com/content/343/bmj.d2090
Visst, det räcker att rapportera koefficient, standardfel och N så kan man räkna fram resten själv. Det tror jag de flesta empiriker gjort själva många gånger. 😉
Låt mig förklara min enkla poäng i inlägget. Ett lågt p-värde uppstår då skattningen är stor i förhållande till standardfelet i skattningen. Detta kan inträffa om man råkar få en väldigt stor skattning (som i fallen med 100 el 1000 obs) eller på grund av att standardfelet är väldigt litet (som i det första fallet ovan). Vad som är ”stort” och ”litet” måste dock utvärderas i förhållande till den sanna effektstorleken, vilken man typiskt sett inte vet. Det är detta jag försöker tydliggöra med simuleringarna och jag hävdar inte att man ska sluta rapportera p-värden, utan att komplettera den med ytterligare information (någon slags bedömning av skattningens precisionen).
Om man gör ett test av proportioner och använder sig av normalapproximation så använder man sig av proportionen under H0 när man gör test och den skattade när man gör konfidensintervall. Så då behöver det inte bli samma sak.
I den mån ditt svar Martin berörde det jag skrev så sätter du fingret på precis min poäng, men drar enligt min mening helt fel slutsats av det. Min tanke är just att om man rapporterar koefficienter och standard fel så kan man sedan räkna ut p-värdet själv. Det finns således ingen anledning att ange detta, då det inte bidrar med någon ytterligare information. Risken är tvärtom att p-värden lurar hjärnan att dela in studier i antingen sanna (p0.05), när svaret sällan är så enkelt.
Om vi igen litar till modern psykologisk forskning så finns det dessutom en poäng med att låta folk räkna ut detta på egen hand, då hjärnan blir mer aktiv om den tvingas tänka. Detta bör innebära att du är mindre benägen att dra elementära felaktiga slutsatser om du först tvingas att faktiskt räkna fram p-värdet innan du tolkar det.
I övrigt står jag fast vid min andra poäng också; det går inte att göra kostnads- intäktskalkyler på p-värden.
Upptäckte precis att kommentarerna inte tillåter ”större än” och ”mindre än” tecken.
”Risken är tvärtom att p-värden lurar hjärnan att dela in studier i antingen sanna (p0.05), när svaret sällan är så enkelt.”
ska egentligen vara
”Risken är tvärtom att p-värden lurar hjärnan att dela in studier i antingen sanna (p mindre än 0.05) eller falska (p större än 0.05), när svaret sällan är så enkelt.”.